












はじめに
文字起こしのための音声認識モデルとしてOpenAIが提供するWhisperが存在しますが、今のところ(2023年9月時点)複数人が話している音声に対してそれぞれを識別することはできません。
そのため議事録などに使おうとするには誰が何を話したかという情報がないためすこし物足りなさを感じます。
今回はpyannote.audioを使って話者を分けて文字起こしするということに取り組んだのでそのことについてまとめます。
pyannote.audioとは
pyannote.audioは話者分離(Speaker Diarization)を実現するための、Pythonによるオープンソースフレームワークです。
以下がGitHubです。
使い方
事前準備
pyannote.audioはHugging Faceが提供しているのでライブラリにアクセスするためにトークンを取得する必要があります。
まずHugging Faceのアカウントを作成し、pyannote.audioを呼び出すために以下2つのリポジトリの利用規約に同意する必要があります。
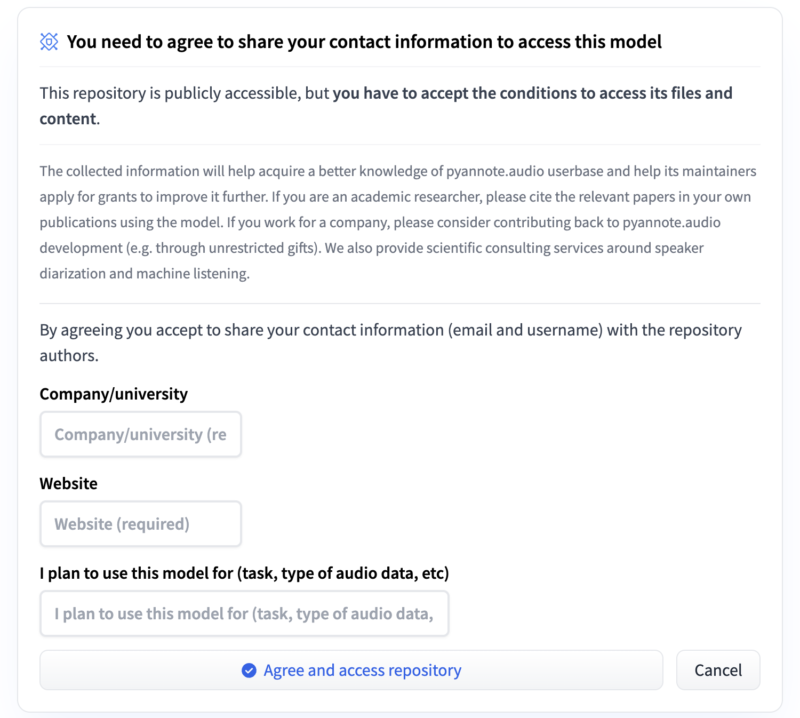
その後設定ページからアクセストークンを発行するとhf_*******のようなトークンが発行されます。
これで準備が整ったので実際に話者分離を実行してみます。
from pyannote.audio import Pipeline
pipeline = Pipeline.from_pretrained("pyannote/speaker-diarization",
use_auth_token="ACCESS_TOKEN_GOES_HERE")
diarization = pipeline("audio.wav")
for turn, _, speaker in diarization.itertracks(yield_label=True):
print(f"start={turn.start:.1f}s stop={turn.end:.1f}s {speaker}")# start=0.2s stop=1.5s SPEAKER_00
# start=1.8s stop=3.9s SPEAKER_01
# start=4.2s stop=5.7s SPEAKER_00
...話者分離自体は数行のコードで完結します。
予め音声ファイルの人数がわかっていれば以下のようにすると話者分離の精度が上がります。
diarization = pipeline("audio.wav", num_speakers=2)Whisperとの組み合わせ
Whisperと組み合わせて話者分離した文字起こしを実施していきます。
Whisperについては以下の記事をご覧ください。
やり方はいろいろあると思いますが、今回は2パターンに絞って話を進めていきます。
まずはpyannote.audioで話者分離をしてから、Whisperでセグメント毎に文字起こしを実施するパターン。もう一つは音声全体をWhisperで文字起こしとpyannote.audioで話者分離してからセグメント毎に統合していくパターンです。
個人的にはパターン2の方が精度が高かったという印象です。
ただデメリットも存在するので利用する際はそこを考える必要はありそうです。
今回サンプルとして使用する音声ファイルはこちらです。(4人の男女の会話)
パターン①
調べていて紹介されている書き方が多いなと思ったのがこちらの話者分離してから各セグメントを文字起こしするパターンです。
この方法が一番簡単だと個人的には思いました。
pynnnote.audioでは、Wave形式の音声ファイルしか扱えないようなので、mp3やmp4の音声を使用する場合はwavに変換する処理が事前に必要です。
import subprocess
def to_wav(input_file_path, wav_file_path):
command = [
"ffmpeg",
"-i",
input_file_path, # 入力音声ファイル
wav_file_path # 出力WAVファイル
]
subprocess.run(command)import whisper
from pyannote.audio import Pipeline
from pyannote.audio import Audio
wav_file_path = "audio.wav"
to_wav(input_file_path, wav_file_path)
model = whisper.load_model("large-v2")
pipeline = Pipeline.from_pretrained("pyannote/speaker-diarization",
use_auth_token="YOUR_AUTH_TOKEN")
diarization = pipeline(wav_file_path, num_speakers=4)
audio = Audio(sample_rate=16000, mono=True)
for segment, _, speaker in diarization.itertracks(yield_label=True):
waveform, sample_rate = audio.crop(wav_file_path, segment)
text = model.transcribe(waveform.squeeze().numpy())["text"]
print(f"[{segment.start:03.1f}s - {segment.end:03.1f}s] {speaker}: {text}")
yield_label=Trueオプションが指定された場合、このメソッドはイテレータを返し、そのイテレータは(segment, track, label)という3要素のタプルを順に返します。
segment: 話者が発話している時間区間(Segment)です。track: この区間において発話している話者や音声のトラック情報(TrackName)です。label: その話者や音声トラックが持つラベル(Label)です。これは通常、話者の識別子やクラス名などです。
このyield_label=Trueオプションにより、各セグメント(時間区間)とトラック名(話者IDなど)に加えて、その話者やトラックが持つラベルも一緒に取得できるようになります。
0.5s - 3.8s] SPEAKER_02: こんにちは。シェアハウスコルサってここですか?
[4.5s - 7.0s] SPEAKER_01: もしかして4人目の住人の人
[7.3s - 11.0s] SPEAKER_02: はい、吉田由里です。よろしくお願いします。
[11.9s - 14.9s] SPEAKER_02: 思ったよりいいとこですねここ
[14.9s - 17.7s] SPEAKER_01: そうでしょう 僕、蝶です
[18.9s - 23.4s] SPEAKER_00: やっと来た。 ゆり、今何時だと思ってる?
[24.1s - 27.8s] SPEAKER_02: ごめんごめん、スティーブ。ついにドネしちゃって。
[28.4s - 29.9s] SPEAKER_00: せめて電話ぐらい
[30.1s - 32.6s] SPEAKER_02: はい、本当にごめんなさい
[33.6s - 37.9s] SPEAKER_01: 二度寝気持ちいいんですよねー 僕もよくやっちゃう
[38.9s - 54.1s] SPEAKER_02: 共有スペースはもう片付いたから、そこにある吉田さんの荷物、自分の部屋に運んでくれる?あ、ユリでいいですじゃあユリさん、お願いね。私はアナアナさん、よろしくお願いしますnum_speaker=4と指定しましたが、3人分しか分離されていませんでした。
また、最後の行は実際は二人の女性が会話している箇所ですが、一人の発言として処理されています。
ところどころ文字起こしが少し違いますが、話者分離は基本的にできていそうです。
これは1分ほどの音声なのでそれほど違和感ないですが、他に10分、1時間の音声ファイルを試して見ましたが、話者分離の精度が悪くなるのもそうですが、文字起こしの精度自体も悪くなるというような結果になりました。
一例ですが、1時間のファイルを処理したときの結果です。
[997.1s - 997.2s] SPEAKER_01: you
[1010.2s - 1011.9s] SPEAKER_02: ポジネが両方ある
[1017.2s - 1018.4s] SPEAKER_01: いいねが普通なんだよ、彼
[1023.1s - 1023.1s] SPEAKER_02: you
[1028.8s - 1030.0s] SPEAKER_02: はいはいはいそうですね
[1036.0s - 1036.3s] SPEAKER_02:
[1039.4s - 1042.0s] SPEAKER_02: 【コメント】サポートとかもすごい大事空白だったりよくわからない文字起こしになったりしています。
パターン②
パターン①だと長尺音声の精度が良くないという結果を受けて別の方法を探っていたところ試したのが、パターン②の音声全体をWhisperで文字起こしとpyannote.audioで話者分離してからセグメント毎に統合していくという方法です。
こちらのライブラリを参考にしました。
import whisper
from pyannote.audio import Pipeline
from pyannote_whisper.utils import diarize_text
pipeline = Pipeline.from_pretrained("pyannote/speaker-diarization",
use_auth_token="YOUR_AUTH_TOKEN")
wav_file_path = "audio.wav"
model = whisper.load_model("large-v2")
asr_result = model.transcribe(wav_file_path)
diarization_result = pipeline(wav_file_path)
final_result = diarize_text(asr_result, diarization_result)
for seg, spk, sent in final_result:
line = f'{seg.start:.2f} {seg.end:.2f} {spk} {sent}'
print(line)
ほとんど処理は同じですが、先にWhisperで文字起こししている点とdiarize_textというメソッドが呼び出されています。
これはpyannote-whisperに存在するutils.pyのメソッドです。
詳しくはGitHubを見ていただければと思いますが、ざっくりやっていることの解説です。
def diarize_text(transcribe_res, diarization_result):
timestamp_texts = get_text_with_timestamp(transcribe_res)
spk_text = add_speaker_info_to_text(timestamp_texts, diarization_result)
res_processed = merge_sentence(spk_text)
return res_processeddiarize_textメソッドとその内部で呼び出されているメソッド群は、Whisperの文字起こし結果(テキストとそのタイムスタンプ)と話者分離の結果を統合して、時間、話者、テキストを関連付け、それを更に結合するというようなことをしています。
diarize_textは4つのステップで処理を行っています。
get_text_with_timestampを呼び出して、文字起こしの結果からタイムスタンプとテキストを取得します。add_speaker_info_to_textを呼び出して、各セグメントに話者情報を追加します。merge_sentenceを呼び出して、同一の話者による連続するセグメントを一つのセンテンスにマージします。- マージされたテキストを返します。
- get_text_with_timestamp(transcribe_res)
Whisperの文字起こし結果から、各単語やフレーズの開始時間(start)、終了時間(end)とテキスト(text)を取得し、それらをSegmentオブジェクトと組にしてリストに格納します。
- add_speaker_info_to_text(timestamp_texts, ann)
get_text_with_timestampで取得したタイムスタンプテキストのリストと、話者分離の結果を引数として受け取ります。各テキストセグメントに対して、最も確率が高い話者(.argmax()で取得)を割り当て、それを新たなリストに格納します。
- merge_sentence(spk_text)
同じ話者による連続したセグメントを一つのセンテンスにマージする役割を果たします。マージの基準は、単語の最後に文末の句読点(、。など)が来た場合や、話者が変わった場合です。
最終的にdiarize_textは、各セグメントがどの話者によるものか、そしてそのテキスト内容が何か、という情報を結合した形で出力する役割を果たします。
先程と同じ音声を実行した結果です。
0.00 4.00 SPEAKER_02 こんにちは。シェアハウスコルサってここですか?
4.00 7.00 SPEAKER_01 もしかして、4人目の住人の人?
7.00 14.00 SPEAKER_02 はい、吉田由里です。よろしくお願いします。思ったより、いいとこですね、ここ。
14.00 18.00 SPEAKER_01 そうでしょ。僕、張です。
18.00 23.00 SPEAKER_00 やっと来た。由里、今何時だと思ってる?
23.00 28.00 SPEAKER_02 ごめんごめん、スティーブ。ついにドネしちゃって。
28.00 30.00 SPEAKER_00 せめて電話ぐらい。
30.00 33.00 SPEAKER_02 はい、本当にごめんなさい。
33.00 38.00 SPEAKER_01 2度寝、気持ちいいんですよね。僕もよくやっちゃう。
38.00 45.00 SPEAKER_02 共有スペースはもう片付いたから、そこにある吉田さんの荷物、自分の部屋に運んでくれる?
45.00 54.00 SPEAKER_02 あ、由里でいいです。じゃあ、由里さん、お願いね。私はアナ。アナさん、よろしくお願いします。パターン①同様4なのに関わらず3人分しか分離されないという結果になりました。
最後の行もセグメントは分かれましたが、同じ人物として処理されています。
女性の声が似ているというのは原因として考えられるかもしれません。
パターン①と同じように10分、1時間の音声で実行してみましたが、パターン①のときに起きていたような空白や「you」のみのよくわからない文字起こしの結果は見当たりませんでした。
音声ファイル全体の文字起こしをWhisperで予め行っているためだと推測しました。
しかし文字起こしと話者分離を別々で行い、それぞれの結果を統合していることで生じる問題もあります。
diarize_textで各セグメントの話者情報を文字起こしの結果とマージしていましたが、該当のスピーカーがマッチしない場合はNoneというように出力されてしまいます。
チューニング
そのままでもある程度話者分離の精度は高いですが、チューニングもできるようになっています。
詳しくは以下のページに載っています。
この中で話者分離パイプラインのハイパーパラメータを調整する記載があります。
https://github.com/pyannote/pyannote-audio/blob/develop/tutorials/adapting_pretrained_pipeline.ipynb
- segmentation.threshold ($\theta$ in the [technical report](https://huggingface.co/pyannote/speaker-diarization/resolve/main/technical_report_2.1.pdf), between 0 and 1) controls the aggressiveness of speaker activity detection (i.e. a higher value will result in less detected speech);
- clustering.threshold ($\delta$ in the report, between 0 and 2) controls the number of speakers (i.e. a higher value will result in less speakers).
- segmentation.min_duration_off ($\Delta$ in the report, in seconds) controls whether intra-speaker pauses are filled. This usually depends on the downstream application so it is better to first force it to zero (i.e. never fill intra-speaker pauses) during optimization.
- clustering.centroid is the linkage used by the agglomerative clustering step. `centroid` has been found to be slightly better than `average`.
- clustering.min_cluster_size controls what to do with small speaker clusters. Clusters smaller than that are assigned to the most similar large cluster. `15` is a good default value.
訳
segmentation.threshold(θ): これは話者の活動検出の厳しさを制御します(高い値ほど話者の検出が少なくなります)。
clustering.threshold(δ): これは話者数を制御します(高い値ほど話者数が少なくなります)。
segmentation.min_duration_off(Δ): これは話者間の一時停止がどれだけ埋められるかを制御します。最適化の初期段階ではこの値を0に設定しています。
clustering.centroid: 凝集型クラスタリングで使用されるリンケージ方法です。centroidはaverageよりわずかに優れているとされています。
clustering.min_cluster_size: 小さな話者クラスタに何をするかを制御します。この値より小さいクラスタは、最も類似した大きなクラスタに割り当てられます。
他にもpyannote.audioのコードを追っていくと初期でどのような値が設定されているかがわかります。
SpeakerDiarizationクラスには以下のようなデフォルト値が設定されています。
class SpeakerDiarization(SegmentationTaskMixin, Task):
"""Speaker diarization
Parameters
----------
protocol : SpeakerDiarizationProtocol
pyannote.database protocol
duration : float, optional
Chunks duration. Defaults to 2s.
max_speakers_per_chunk : int, optional
Maximum number of speakers per chunk (must be at least 2).
Defaults to estimating it from the training set.
max_speakers_per_frame : int, optional
Maximum number of (overlapping) speakers per frame.
Setting this value to 1 or more enables `powerset multi-class` training.
Default behavior is to use `multi-label` training.
weigh_by_cardinality: bool, optional
Weigh each powerset classes by the size of the corresponding speaker set.
In other words, {0, 1} powerset class weight is 2x bigger than that of {0}
or {1} powerset classes. Note that empty (non-speech) powerset class is
assigned the same weight as mono-speaker classes. Defaults to False (i.e. use
same weight for every class). Has no effect with `multi-label` training.
warm_up : float or (float, float), optional
Use that many seconds on the left- and rightmost parts of each chunk
to warm up the model. While the model does process those left- and right-most
parts, only the remaining central part of each chunk is used for computing the
loss during training, and for aggregating scores during inference.
Defaults to 0. (i.e. no warm-up).
balance: str, optional
When provided, training samples are sampled uniformly with respect to that key.
For instance, setting `balance` to "database" will make sure that each database
will be equally represented in the training samples.
weight: str, optional
When provided, use this key as frame-wise weight in loss function.
batch_size : int, optional
Number of training samples per batch. Defaults to 32.
num_workers : int, optional
Number of workers used for generating training samples.
Defaults to multiprocessing.cpu_count() // 2.
pin_memory : bool, optional
If True, data loaders will copy tensors into CUDA pinned
memory before returning them. See pytorch documentation
for more details. Defaults to False.
augmentation : BaseWaveformTransform, optional
torch_audiomentations waveform transform, used by dataloader
during training.
vad_loss : {"bce", "mse"}, optional
Add voice activity detection loss.
Cannot be used in conjunction with `max_speakers_per_frame`.
metric : optional
Validation metric(s). Can be anything supported by torchmetrics.MetricCollection.
Defaults to AUROC (area under the ROC curve).
References
----------
Hervé Bredin and Antoine Laurent
"End-To-End Speaker Segmentation for Overlap-Aware Resegmentation."
Proc. Interspeech 2021
Zhihao Du, Shiliang Zhang, Siqi Zheng, and Zhijie Yan
"Speaker Embedding-aware Neural Diarization: an Efficient Framework for Overlapping
Speech Diarization in Meeting Scenarios"
https://arxiv.org/abs/2203.09767
"""ハイパーパラメータやSpeakerDiarizationの値を調整して結果を検証していくと精度の向上は見込めそうです。
最後に
pyannote.audioとWhisperを組み合わせて話者分離して文字起こしする方法を解説しました。
個人的にはパターン②の方が精度が良かったという感じでした。
完全に納得のいく結果というわけではなかったですが、誰が何を話したというのを理解するには十分な結果だったかなと思います。
ファインチューニングまではしていませんが、パラメータをいじって値を検証するということで多少の改善はあったと感じています。
私自身、機械学習を専門としているわけではないのでまだ理解しきれていないところもありますが、調べていく中でどのようなことが行われているかをざっくり把握することはできました。
今後ファインチューニングにも取り組んでみたいと思いました。

コメント